The concept of cloud services for business applications is as simple as moving the application servers from the on-premises network to the Internet. The end users continue working with the same software (either the native client or the web client); the only thing required is an Internet connection. They no longer need to log on to the local enterprise network (directly or through VPN). Moreover, if the enterprise uses the
SaaS model, the end users do not need to worry about software administration and updates any longer—the cloud service provider hosting your application servers will manage these tasks.
 Eye catcher image: the author of this article illustrates the "1C:Enterprise in the cloud" concept by using simple objects: clouds, banner, aircraft, parachute.
Eye catcher image: the author of this article illustrates the "1C:Enterprise in the cloud" concept by using simple objects: clouds, banner, aircraft, parachute.1C:Enterprise applications support both HTTP and HTTPS connections, making for a seamless transition of 1C:Enterprise application servers to the Internet. That's all you need to create a basic 1C:Enterprise cloud solution.
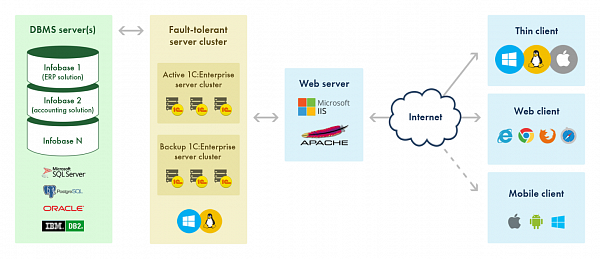
The only difference between this scenario and the on-premises installation is the location of the application server. To provide a service to a new company, one needs at least a new 1C:Enterprise infobase and a physical computer or a virtual machine running 1C:Enterprise. Therefore, application administration costs grow with the number of companies that utilize the service.
Multitenancy and data separation
To reduce application administration costs, you can now have multiple companies work with a single application instance. Of course, the application must be designed for shared work. And the application business logic in the shared work scenario must be identical to the business logic in the scenario where each company uses its own application.
This application architecture type is known as
multitenancy. We can explain the multitenancy concept using the following example: a regular application is a house that provides its infrastructure (walls, roof, water system, heating system, etc.) to a family that lives there. A multitenant application is a house with multiple apartments, each apartment having access to the same shared infrastructure that is implemented at the basic house level.
In the simplest terms, the goal of multitenancy is reducing application maintenance costs by pushing the infrastructure maintenance to a higher level. It is similar to reducing costs by selling standard out-of-box applications (that might require some customization) instead of writing applications for specific customers from scratch. The difference is that out-of-box solutions reduce the development cost, while cloud solutions reduce the maintenance cost.
One of the multitenancy aspects is the separation of application data. An application stores data of all companies in a single database, however, each company can only access its own data (such as business documents and employee lists). Some reference data (such as legislation and regulations) can be made available to all companies. 1C:Enterprise applications can use the data separation functionality provided by the 1C:Enterprise platform.
Cloud services
Recently, a group of 1C:Enterprise developers faced the task of developing a cloud service for leasing 1C:Enterprise applications based on SaaS model. Moreover, the service needed to be an out-of-box solution, a "cloud in the box" including everything the customer may need to deploy infrastructure for leasing 1C:Enterprise applications (or individual applications based on 1C:Enterprise).
So what is an ideal cloud service from the end user's point of view? A store with shelves filled with solutions: accounting, reporting, payroll and human resources, and so on. A customer fills their cart and pays at the cash desk (however, they pay a rent instead of a one-time payment). Then the customer decides which of their employees will have access to accounting, payroll, and HR, as well as other solutions.
What is an ideal cloud service from the service provider's point of view? Basically, it's a large store they own. They have to fill the shelves with goods (software), add new goods, and make sure the customers pay promptly. The service must also provide horizontal scalability, access to solution demos (test drive), and centralized user administration tools.
Of course one can implement all this functionality directly in the applications. However, this means duplicating a large amount of code. It is better to optimize the solutions by implementing their common functionality and administration tools in a product that will serve as an entry point for users of cloud services.
This is how 1cFresh technology was developed. 1C customers and partners use it in their SaaS services and
private clouds. 1C Company has its own application lease service based on 1cFresh:
1cFresh.com and
1C:AccountingService (both in Russian).
The service functionality is divided between the following major components based on 1C:Enterprise and Java technologies:
- Service website. A single entry point for all users.
- Service manager. An administration and coordination tool governing all service components.
- Application gateway. The component that provides horizontal scalability.
- Service agent. The component that provides all utility functions, such as application version updates or backup creation.
- Service forum. A forum for service users and service provider representatives.
- Availability manager. The "Service temporarily unavailable" board that informs users about service unavailability or the unavailability of service parts, the board itself is available even if central service components have failed.
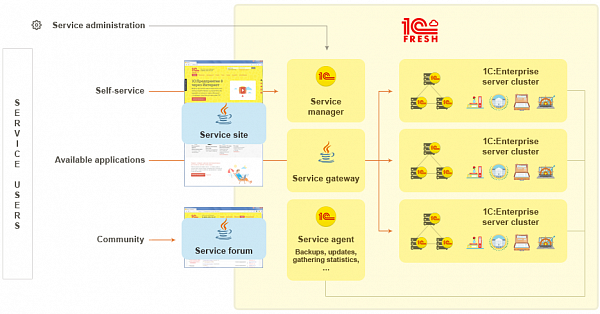 Simplified 1cFresh component chart (with some components omitted)
Simplified 1cFresh component chart (with some components omitted)Let us review the major service components in detail.
Service websiteThe site that provides the interface for service users is written in Java. It serves as a store shelf where users can choose applications to rent and try their demos. In addition to that, it is where users register, create application user accounts, read news and browse service online help. The
1cFresh.com page (in Russian) is exactly the "out-of-box" website, without any customizations.
A service can include any number of 1C:Enterprise server clusters that run 1C:Enterprise applications. Each cluster is registered in the service manager. 1C:Enterprise servers can run on both Windows and Linux computers. For example, the service at 1cFresh.com uses both Windows servers (with MS SQL Server DBMS for storing application data) and Linux servers (with PostgreSQL).
The cloud service administrators access the service via the service manager user interface. They use it to add 1C:Enterprise servers and applications, update application versions, manage user accounts, and perform other administrative tasks. Some of the operations, such as application updates, are delegated to the service agent component. The service manager communicates with the service agent via a web service.
Service agentThe service agent is a 1C:Enterprise application. It performs administrative operations on the service infobases, which include application version updates, scheduled backups, and gathering service operation statistics.
Application gatewayThe application gateway is written in Java. It is responsible for the horizontal scalability of the service. It redirects service users to appropriate application servers.
Service forumThe service forum is a location where service users and service provider representatives can discuss the service and the applications available in that service. It is written in Java.
Availability managerSome service features or even the entire service might be temporarily unavailable to end users. For example, an application is usually unavailable to end users while it is being updated, or the entire service might be unavailable during maintenance hours. The availability manager is a 1C:Enterprise application that displays messages about the unavailability of service resources to website and forum users even if all other service components, including the central service manager component, are not available.
1C:Enterprise infobases1C:Enterprise infobases store application data. New infobases are added to serve as parts of scalability units. Each scalability unit is deployed as a single module and contains the following parts:
- 1C:Enterprise server cluster
- DBMS server that stores infobase data
- One or two web servers (two ensure fault tolerance) that process HTTP requests to infobases belonging to the scalability unit
A scalability unit failure only affects the customers that work with the infobases belonging to the unit.
More service facts
- The service supports a technology similar to OpenID that allows storing user authentication data in a single database. Therefore, you can set up Single Sign-On for the service and its users will be able to access all their applications (for example, accounting or payroll calculation) and the forum with a single user name and password.
- Users can transfer local 1C:Enterprise application data (for example, accounting records) to the cloud and back.
- Users can create standalone workstations (file infobases stored at their local computers). They do not need the Internet or service connections to work with such infobases. At the same time, they can use the service data exchange functionality to synchronize their local data with the cloud.
- Users can set up automatic data exchange between the applications published in the service (for example, between accounting and payroll calculation applications). This minimizes the efforts required to input data because data entered into one application becomes available for all other applications.
- A backup creation system is available. A user can initiate backup creation at any time, or schedule daily, monthly, and yearly backups.
- The 1cFresh technology includes the data delivery feature. The service manager stores reference data that is always up-to-date and provides this data to all applications.
- A service can run multiple versions of any application. These applications can use multiple 1C:Enterprise platform versions.
- Users can update the applications that they use to access their infobases.
- 1cFresh features the following tools for error identification and analysis:
- Gathering infobase error data.
- Writing this data to the error log of the service manager infobase.
- Viewing error details. A service administrator can view the entire error log or filter it by infobase or application.
- 1cFresh includes the "showcase" feature, which provides the option to run multiple cloud services on a single platform. A showcase is an Internet resource that provides services. From the user’s point of view, a showcase is an independent website with business applications. For example, a single website platform that belongs to a service provider can run several sites located in different domains, one featuring a showcase of small business applications, another with applications for public institutions, the third one with applications for medical institutions, and so on. Also, service providers can advertise each resource as an independent service.
- The service includes a Feedback center where users can submit their feedback and feature requests. It is implemented as an application module that features a list of user posts and comments to these posts, voting for posts and commenting on them, as well as submitting feedback and feature requests. To include this functionality in an application, an administrator simply enables the subsystem where it is implemented.
- Subscribers of 1cFresh-based services pay a subscription fee to the service provider. Flexible pricing options are available.
- The service provides a wide range of options for viewing its usage statistics. One can use the statistics to determine the service load, obtain average key indicators of stable service work (for future evaluation of possible deviations), determine the periods of minimum and maximum service load (for planning scheduled maintenance), and more.
- The option to gather application business statistics is available. Application developers can use the statistics to improve their understanding of application usage scenarios and to identify bottlenecks.
Applications compatible with cloud services
To be able to run in the cloud, 1C:Enterprise applications must meet the SaaS mode requirements. For the detailed list of requirements, see 1cFresh documentation.
The requirements include the use of data separation functionality, as well as implementations of remote administration functions, data import and export, backup generation, and more. Cloud applications must offer identical behavior between the thin client and the web client, they must not include OS-dependent features (because a cloud server might run either Windows or Linux), lengthy server calls are not recommended, and so on.
Cloud applications can have mobile application clients developed using the
mobile 1C:Enterprise platform.
Cloud application customizationThousands of users from hundreds of companies can work with a single cloud application instance. They might require custom application features. Thus, service providers need tools to customize applications for certain user groups.
1cFresh provides two kinds of application customization tools:
- External reports and external data processors. These customization tools, well known to 1C:Enterprise application users, were enhanced for cloud operations.
- Configuration extensions. Extensions are plug-ins that add functionality to applications without changing them. Currently, extensions do not support all of the configuration objects, however, we are working on making this function available.
Summary
We believe cloud service development to be a promising trend worthy of significant resource investment.
1cFresh cloud service fully complies with the
cloud service definition provided by
IDC:

According to the
Gartner definition, 1cFresh service type is an Application Platform that operates as a Service (
aPaaS): "Application Platform as a Service (aPaaS) is a form of PaaS that provides a platform to support app development, deployment and execution in the cloud." (
source)